jackyko1991.github.io Biomedical Image Computation 101
HPC Cluster Setup Part 1 - The Basics
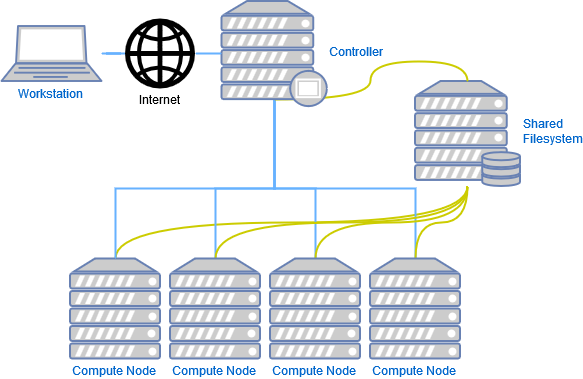
High performance computing (HPC) refers to the high speed calculations and data processing ability. A modern PC or even mobile devices could provide up to 5 billions calculations per CPU core per second, and a more powerful workstation could assemble more than 50 CPU cores and multiples GPU in a single chassis unit. However the computation power of a single PC is still limited, how could we boost up the calculation speed when we have multiple devices? The solution is the concept of HPC clusters.
Content
- How Does HPC Cluster Work?
- How to Maximize the HPC Ability?
- When will I Need a HPC cluster for Computational Radiology?
- Selection of Distributed Resources Management Software
How Does HPC Cluster Work?
The HPC cluster is an assembly of one or more computational devices, which can be divided into three main components:
- Nodes
- Network
- Storage

The HPC architecture connects multiple computers via networks to form a cluster. In clustering we name the computers as “nodes”. Each node may carry specific functions including job scheduling and distribution, GPU computation, heterogeneous CPU architecture computations (ARM, FPGA nodes) and data storage. Even though individual devices may only carry very low computational ability, every node is playing an important role in terms of resource leveraging. The components operate seamless together to complete a diverse set of tasks.
Detailed device list of HPC cluster

- Headnode or login node, where users log in
- Specialized data transfer node
- Regular compute nodes (where majority of computations is run)
- “Fat” compute nodes that have at least 1TB of memory
- GPU nodes (on these nodes computations can be run both on CPU cores and on a Graphical Processing Unit)
- Switch and router to connect all nodes
How to Maximize the HPC Ability?
To maximize the power of HPC clusters, one may put every nodes in full loading whole time and keep each components keep pace with each others. The data storage nodes take responsibility of raw data ingestion and analyzed data output. To transfer data among storage nodes and computational nodes, a fast network and caching technique for data input/output is one of the keystones to boost up processing speed. To maintain such coordinated works, a bunch of software toolkits are developed to automate the process.
When will I Need a HPC cluster for Computational Radiology?
Take a look at this post. Docker container is an easy to use tool for AI development, all environments are ready with single docker pull command. This is only the case when computational resources are readily available, however this is never a case comes to GPU computation. Imagine 20 PhD students in same department share a 8 card PC, this will eventually result in computer resources monopolization. The scheduling technique in HPC clusters could bring in a fair usage environment to every user of the shared devices.
Selection of Distributed Resources Management Software
There are a number of cluster resources management systems available under Linux:
- Task scheduler:
- Container Solution:
- and more…

Each of the resource management system has it’s unique features. The combined usage of Kubernetes and Singularity with Docker provides flexible cluster orchestration as a container solution. What if I am only a small development team and wish to automate GPU scheduling? Slurm do support GPUs as the GRES (generic resource) and thus would be the preferable management tool for small cluster system. Slurm also has been supported by the most popular cloud services providers including AWS, Azure and GCP, thus provides high flexibility to mix private and public clusters.

In the coming posts there will be hand on steps to setup a Slurm cluster.
References
- Building a Raspberry Pi Cluster
- Deploying a Burstable and Event-driven HPC Cluster on AWS Using SLURM, Part 1
- Deploying a Burstable and Event-driven HPC Cluster on AWS Using SLURM, Part 2
- Run Swarm and Kubernetes Interchangeably
- Integrating Kubernetes with Docker Enterprise Edition 2.0 – Top 10 Questions from the Docker Virtual Event